We propose pix2pix-zero, a diffusion-based image-to-image approach that allows users to
specify the edit direction on-the-fly (e.g., cat to dog). Our method can directly use pre-trained text-to-image diffusion models, such as Stable Diffusion, for editing real and synthetic images while preserving the input image's structure. Our method is training-free and prompt-free, as it requires neither manual text prompting for each input image nor costly fine-tuning for each task.
TL;DR: no finetuning required; no text input needed; input structure preserved.
Abstract
Large-scale text-to-image generative models have shown their remarkable ability to synthesize diverse and high-quality images.
However, it is still challenging to directly apply these models for editing real images for two reasons.
First, it is hard for users to come up with a perfect text prompt that accurately describes every visual detail in the input image.
Second, while existing models can introduce desirable changes in certain regions, they often dramatically alter the input
content and introduce unexpected changes in unwanted regions.
In this work, we propose pix2pix-zero, an image-to-image translation method that can preserve the content of the original image
without manual prompting. We first automatically discover editing directions that reflect desired edits in the text embedding space.
To preserve the general content structure after editing, we further propose cross-attention guidance, which aims to
retain the cross-attention maps of the input image throughout the diffusion process. In addition, our method does not need
additional training for these edits and can directly use the existing pre-trained text-to-image diffusion model.
We conduct extensive experiments and show that our method outperforms existing and concurrent works for
both real and synthetic image editing.
SIGGRAPH 2023 Talk
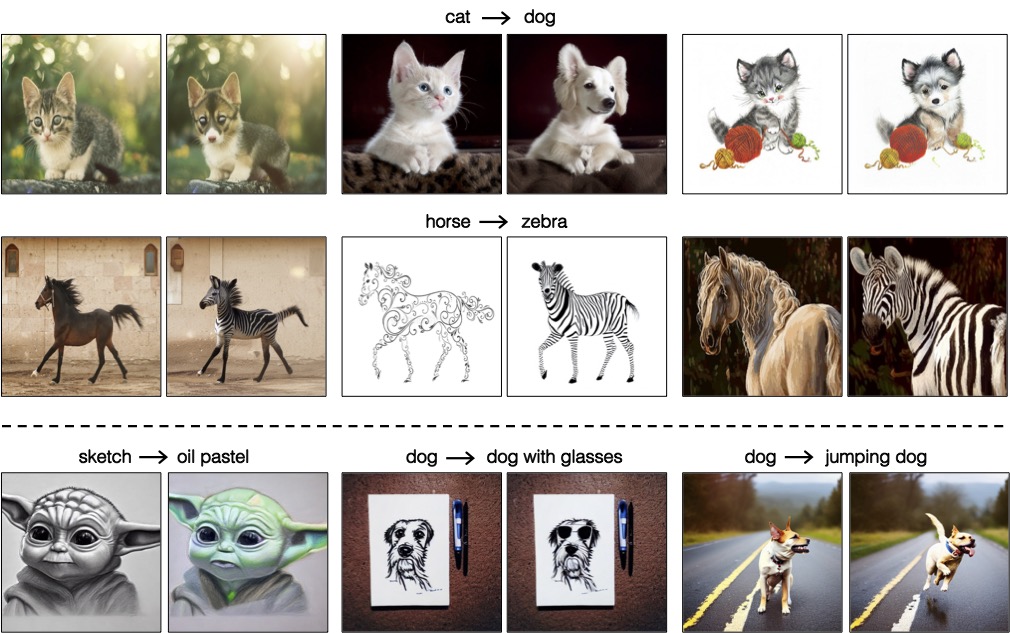
Results: real and synthetic image editing
[ Hover over the image to see the edits! ]
person robot
dog cat
cat dog
cat low poly cat
cat cat drinking boba
cat cat wearing a suit
cat cat wearing a hat
cat crochet cat
zebra horse
horse zebra
tree tree during fall
[The first row for each task is real images, and the second row shows edits on synthetic images.]
Method
Given an input image, we first generate text captions using BLIP and apply regularized DDIM inversion to obtain
our inverted noise map. Then, we obtain reference cross-attention maps that correspoind to the structure of the
input image by denoising, guided with the CLIP embeddings of our generated text (c). Next, we denoise with edited
text embeddings, while enforcing a loss to match current cross-attention maps with the reference cross-attention maps.
For more details, please refer to our paper.
More Results: real image editing
More Results: synthetic image editing
Comparisons with SDEdit, DDIM, and prompt-to-prompt